
Introduction
Artificial intelligence (AI) in medicine has increased enormously in recent years with the development of various AI-based applications and technologies designed to improve patient care and evidence-based medical data. According to experts, artificial intelligence, particularly large learning-based language models, has the potential to transform the global healthcare sector, augment human knowledge, and ultimately improve the quality of life for many patients [1, 2]. Large language models (LLMs) can analyse large data sets to synthesize text responses similar to human communication [3]. One of these models, ChatGPT (OpenAI, San Francisco, CA, USA), was released in November 2022 and has since become one of the most popular LLMs. In the face of rapid technological development, OpenAI launched a new version of its LLM, ChatGPT-4, on 14 March 2023, which proved to be much more advanced than the previous one [4, 5]. Although AI-driven chatbots can address the questions and concerns of medical patients and might revolutionize the way patients interact with medical professionals, the literature data on their use in dermatology is still sparse [6]. One of the dermatologic conditions with multifactorial, devastating effects on patients’ lives, with multiple often ineffective therapeutic options that leave patients with numerous questions, is hidradenitis suppurativa (HS) [7, 8].
Hidradenitis suppurativa, also known as acne inversa, is a chronic, progressive, debilitating, recurrent inflammatory skin disease characterized by the appearance of very severe, persistent, painful nodules, abscesses, and fistulas, most commonly occurring in the skin folds of the axilla, groin, buttocks and perianal area. The estimated range of prevalence is 0.00033–4.1% [7]. However, it should be emphasized that the prevalence of the disease is less than 1% in the vast majority of studies [8]. Due to an average delay of 7 years in correct diagnosis and often ineffective therapies, patients’ quality of life is significantly affected [7]. One of the ways to improve it may be to enhance patients’ knowledge of the disease [9–11]. The literature indicates that patients often look for sources of information outside the doctor’s office, mostly on the Internet [12–14]. Considering the above information and the fact that the user base of ChatGPT is growing very rapidly, we expect that patients will use ChatGPT as a source of information for dermatologic conditions, including HS. Determining the validity of this new tool is therefore essential.
Aim
The study aimed to evaluate the effectiveness of ChatGPT-4 in answering common patient queries (CQs) about acne inversa, comparing the responses of a dermatologist and an artificial intelligence chatbot in terms of quality, empathy, and satisfaction.
Material and methods
A group of 30 patients from the Facebook support group for hidradenitis suppurativa and 31 physicians independently assessed and compared the quality, empathy, and satisfaction of ChatGPT-4 and dermatologist’s responses to common patient queries in the single-blind study.
Collection of questions and answers
The study was conducted from 1 August to 30 September 2023. Twenty of the most frequently asked questions were taken from the Facebook support group for hidradenitis suppurativa and the book “Hidradenitis Suppurativa” by Revuz et al. [15]. The questions were curated, reviewed, and approved by two licensed medical professionals and authors (M. L., P. Ł.) to assess their inclusion in the study. First, the original text of the questions was entered into a new chatbot session (version GPT-4, OpenAI) that did not contain any previous data that could influence the answers. Then, the dermatologist was asked to answer the same questions as he would answer the patient during the visit, creating a simulation of a doctor’s consultation. The questions and the following answers were saved in a text document and are indicated in a supplementary file. The questions were asked in Polish, however, because of the manuscript language they are mentioned in the supplementary file in English.
Survey and evaluation of the answers
The survey was conducted via an anonymous questionnaire, containing questions and answers, created using a Google form. The survey was made available for evaluation to patients of the Facebook support group for hidradenitis suppurativa as well as general practitioners and dermatologists. Respondents were asked to fill out the questionnaire and rate the answers without obtaining any information about their sources beforehand to minimize bias. In addition, the responses for each of the 20 questions were labelled “Answer 1” or “Answer 2” and randomized without any information that could indicate their source (such as claims like “I am an artificial intelligence”). Each response was rated on a five-point Likert scale (1: strongly disagree; 2: disagree; 3: neither agree nor disagree; 4: agree; 5: strongly agree) for [1] quality, [2] empathy, and [3] satisfaction of patients and [1] quality and [2] empathy of physicians. Patients also rated which of the two answers they would prefer to receive for each question. Additionally, on the last page of the survey, without the ability to go back to evaluate responses, the question was asked: “Given that AI can answer your questions more accurately and empathetically than a doctor, who would you rather receive an answer from, a doctor or an artificial intelligence?” (Figure 1).
Statistical analysis
All statistical calculations were performed with Statistica version 12.0 (StatSoft, Tulsa, OK, USA) and a Microsoft Excel spreadsheet. The significance of differences between the two independent groups was tested by the Mann-Whitney U test. The significance of differences between the two dependent groups was tested by the Wilcoxon test. In all calculations, the significance level was set at p = 0.05.
Results
The study ultimately included 30 patients and 31 physicians (21 dermatologists and 10 health care practitioners), who rated each of the two answers to each of the 20 questions, with no idea that ChatGPT-4 might have generated either of them.
Patients’ evaluation on a five-point Likert scale of responses provided by the ChatGPT-4 and the dermatologist
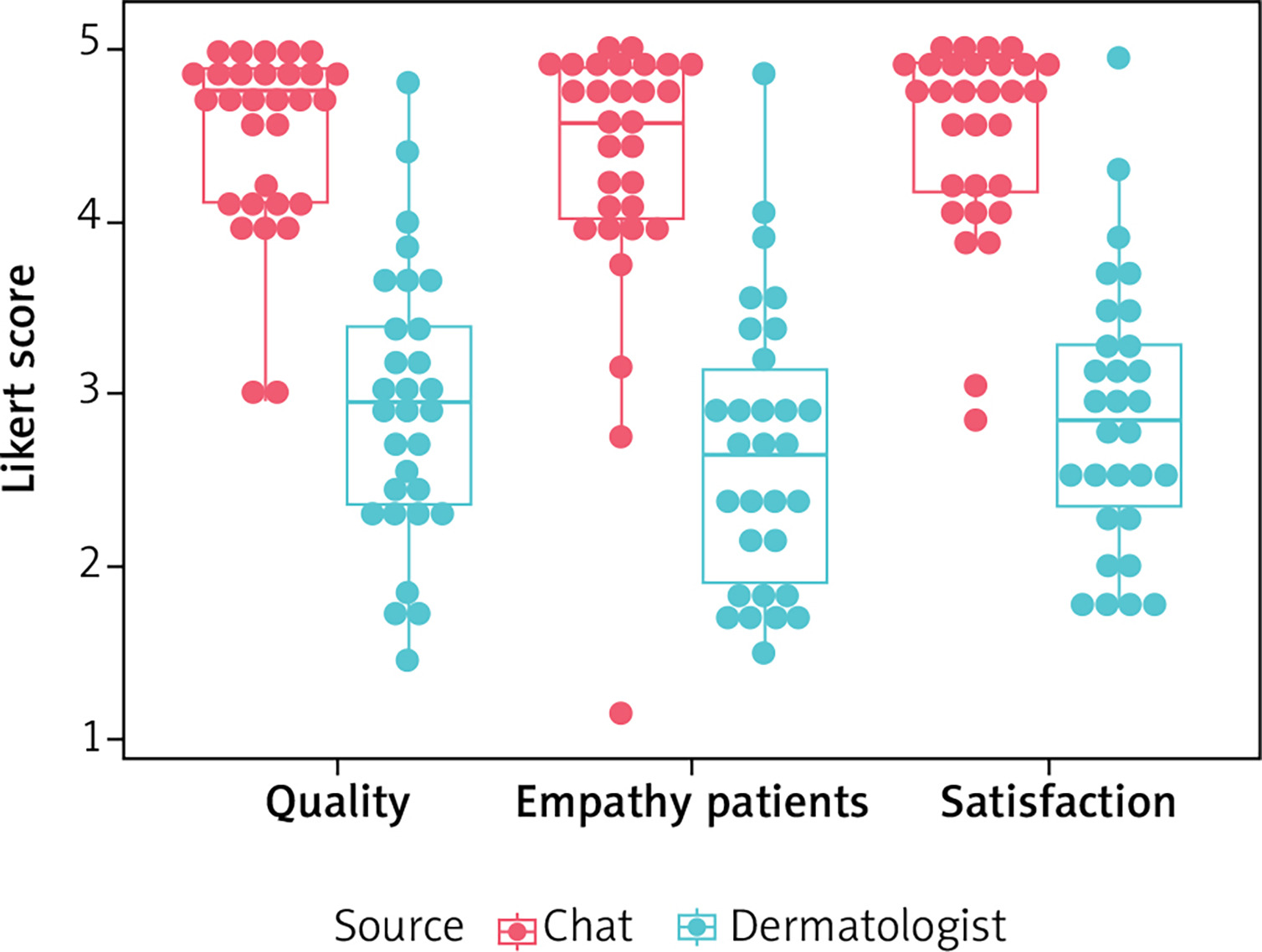
Patients rated the quality of responses provided by ChatGPT-4 and dermatologist as a mean of a Likert scale 4.49 (95% CI: 4.29–4.69) vs. 2.92 (95% CI: 2.63–3.22), respectively. In terms of the response empathy and patients’ satisfaction, the results were as follows: 4.31 (95% CI: 4.01–4.62) vs. 2.66 (95% CI: 2.35–2.97), and 4.5 (95% CI: 4.29–4.7) vs. 2.87 (95% CI: 2.58–3.16), respectively. The above results indicate that for each variable, patients rated the answers generated by ChatGPT-4 statistically significantly better than the answers provided by the dermatologist (p < 0.00001 for each variable) (Table 1, Figure 2).
Table 1
Patients’ and medical doctors’ evaluation on a five-point Likert scale of responses provided by the ChatGPT-4 and the dermatologist. Patients rated responses in terms of quality, empathy, and satisfaction, however medical doctors only in terms of quality and empathy
Doctors’ evaluation on a five-point Likert scale of responses provided by the ChatGPT-4 and the dermatologist
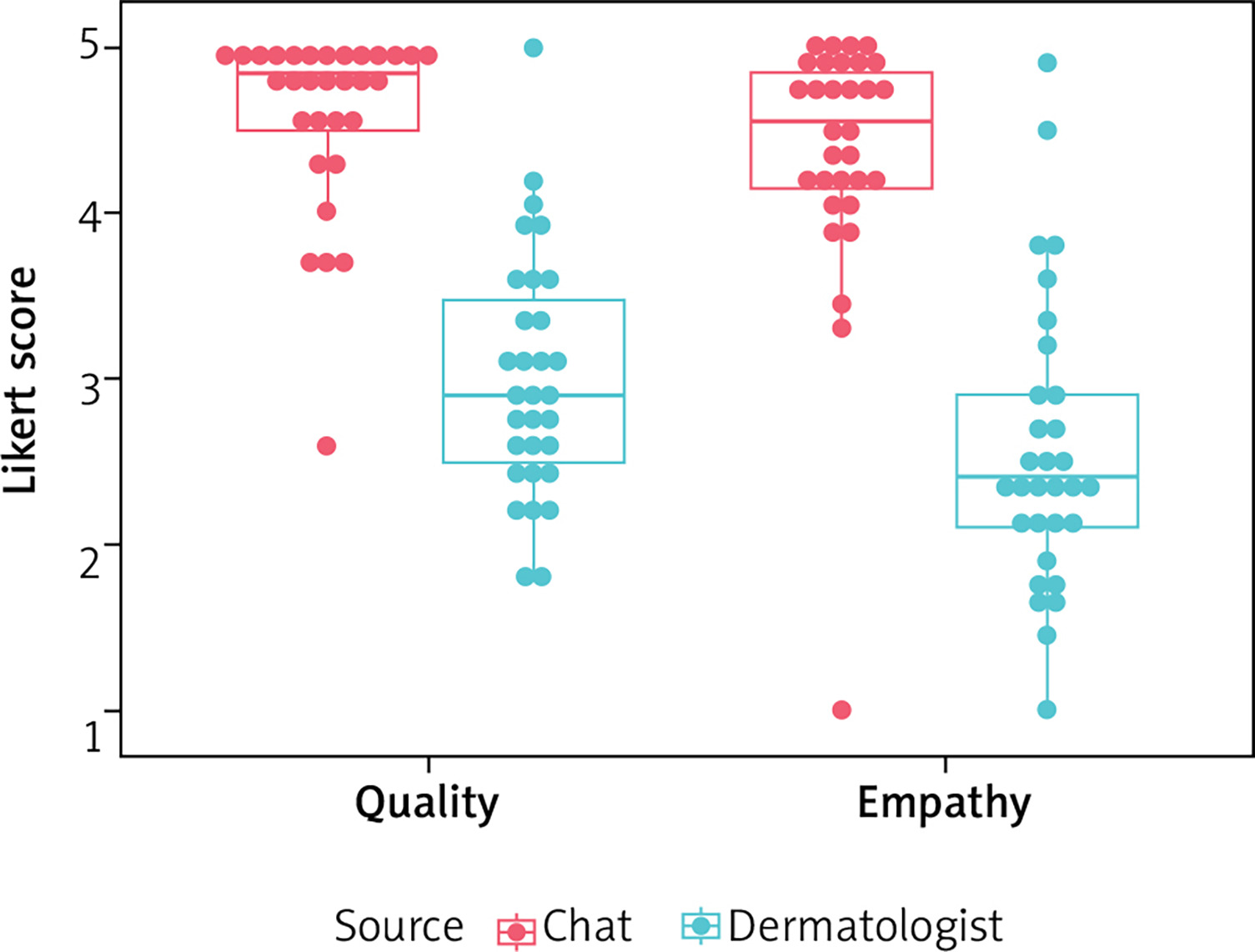
Medical doctors rated responses provided by ChatGPT-4 vs. dermatologists as more qualitative as a mean of a Likert scale 4.6 (95% CI: 4.4–4.8) vs. 3.00 (95% CI: 2.74–3.27), respectively. In terms of the response empathy, the results were: 4.37 (95% CI: 4.08–4.65) vs. 2.57 (95% CI: 2.25–2.89), respectively, for ChatGPT-4 vs. dermatologist. Same as patients, for each variable, medical doctors, rated the answers generated by ChatGPT-4 statistically significantly better than the answers provided by the dermatologist (p < 0.00001 for each variable) (Table 1, Figure 3).
Comparison between patients’ and medical doctors’ evaluation on a five-point Likert scale of responses provided by the ChatGPT-4 and the dermatologist in terms of quality and empathy
There were no significant differences between patients’ and medical doctors’ ratings of ChatGPT-4’s and dermatologist’s responses in terms of both quality and empathy (p > 0.05) (Table 2).
Table 2
Comparison between patients’ and medical doctors’ evaluation on a five-point Likert scale of responses provided by the ChatGPT-4 and the dermatologist in terms of quality and empathy
Which of the two answers patients would prefer to receive to each provided question?
Moreover, when asked which of the two answers patients would prefer to receive, they chose the answers generated by ChatGPT-4 out of an average of 88.33% of the questions, and only out of an average of 11.67%, they chose the answers provided by the dermatologist.
Responses to the last question “Given that AI can answer your questions more accurately and empathetically than a doctor, who would you rather receive an answer from, the doctor or the AI?”
Among 30 patients, 21 people chose the answer that despite the lower quality and empathy, they would prefer to get an answer from a medical doctor. Among medical doctors, 25 chose they would prefer to get an answer from a medical doctor while 6 chose AI.
In addition, the proportion of responses rated less than acceptable quality (on a Likert scale < 3) was higher for the dermatologist than for ChatGPT-4: 36.72% (95% CI: 28.58–44.86) vs. 2.05% (95% CI: 1.35–2.75). Moreover, in terms of empathy, the trend was similar also in favour of ChatGPT-4, which according to respondents, generated only 5.1% (95% CI: 3.89–6.27) of answers rated less than acceptable vs 50.74% (95% CI: 43.11–58.37) provided by the dermatologist. In both, quality and empathy in above 85% of ChatGPT-4 responses were evaluated as good or very good (≥ on a Likert scale) vs. 37% and 26%, respectively for quality and empathy of the dermatologist’s responses.
To evaluate the agreement between raters Kendall’s W test was conducted (Table 3). The p-value for each coefficient was < 0.001. Results indicate moderate or good agreement between raters, both in groups of patients, physicians and all combined.
Table 3
Patients, medical doctors, and all combined agreement in terms of the assessment: quality of AI answers, empathy of AI answers, quality of the dermatologist’s answers, empathy of the dermatologist’s answers
Discussion
As far as we know, this study is the first to show that a conversational AI program derived from LLMs can answer the most frequently asked questions about hidradenitis suppurativa in an easily understandable, scientifically appropriate, and generally satisfactory way. A group of 31 physicians and 30 patients from a Facebook support group for hidradenitis suppurativa independently evaluated and compared the quality, empathy, and satisfaction of ChatGPT-4’s and dermatologist’s responses to patient queries in a single-blind study.
In the study, we found that the quality and empathy of ChatGPT-4’s responses to hidradenitis suppurativa common queries were rated significantly higher by both groups of raters, patients and physicians. In addition, patients were also significantly more satisfied with the chatbot’s responses. Similar studies evaluating the effectiveness of the LLM chatbot in answering questions have been published in the fields of: gastroenterology [16], surgical oncology [17], bariatric surgery [18], plastic surgery [19], urology [20], and even in the field of dermatology [21]. In each of the above areas, only single studies have been published, furthermore most of them were based on an inadequate question scoring system, with no comparison of AI responses with human ones. Compared to the currently published studies [16–22], the responses in our review were rated not only by physicians but also by patients. Moreover, only two of the mentioned studies, by Ayers et al. [22] and Lee et al. [16], evaluated the responses not only for quality but also for empathy and satisfaction. In the study by Lee et al., the gastroenterologists rated the ChatGPT responses similarly to the non-AI responses in terms of scientific appropriateness, satisfaction with the responses, and comprehensibility, with AI averages higher than the non-AI responses [16]. In the study by Ayers et al. [22], the raters evaluated the chatbot responses significantly higher than the physicians’ in terms of quality and empathy, similar to our research. In addition, the raters also preferred the chatbot’s answers to the physician’s. The main difference was that our raters included both patients and physicians, i.e. a total of 61 people evaluated the answers to 20 questions, whereas in Ayers et al. research 3 licensed medical professionals rated 195 questions. Regardless of the study methods, most of them evaluating ChatGPT responses agree that ChatGPT’s ability to provide high-quality responses is satisfactory. This demonstrates the possibilities of using ChatGPT as a resource for information about medical conditions and suggests the potential role of conversational artificial intelligence programs in optimizing communication between patients and healthcare providers.
It is crucial to emphasize that most of the data published in the literature on the implementation of LLM models in medicine is based on the old version, i.e. ChatGPT-3.5. Since there is some evidence that the performance of the newer ChatGPT-4 is significantly better, we should use the latest versions of AI-based technologies to properly assess the possibilities of implementing this type of tool in medicine. Although only one similar study by Seth et al. was also conducted with the new version of ChatGPT, the vast majority of studies conducted with the older LLM model also showed satisfactory results [19].
Our study has shown that despite the better evaluation of AI, patients still prefer doctors as a source of information and answers. Samaan et al. and Mondal et al. also concluded that chatbots are undoubtedly helpful, but are not yet able to replace doctors [18, 23].
In light of the published literature, our findings and the conclusions of other researchers, we believe that AI software should only use peer-reviewed, published data as sources of medical information and that references should be included so that the origin of the information is transparent. The quality and reliability of chatbot’s responses can be further improved if doctors can influence the sources used in large language models. AI chatbots could facilitate the dissemination of up-to-date knowledge not only among patients but also among physicians. Based on the latest guidelines and recommendations, they would allow physicians to find reliable information while minimizing the time spent searching for it [3, 24].
The health literacy, defined as personal knowledge and the competence to use, understand, critically evaluate, and correctly apply information and services to promote and maintain health in daily life is of crucial importance, especially for patients with chronic diseases [25–28]. Patients with higher levels of health literacy through shared decision-making are more likely to adhere to treatment by adopting a better lifestyle and recognizing their disease management skills [29, 30]. Creating a sustainable environment for educating patients with hidradenitis suppurativa through the establishment of support groups and educational events is effective and well-received by participants [26]. However, these interventions require humans (especially healthcare providers such as physicians, nurses, and psychologists), time, and financial resources to implement. ChatGPT-4 has a promising role in increasing health literacy among patients by providing immediate and reasonably reliable access to essential medical knowledge and education [31]. This is especially beneficial for patients living in regions where healthcare access is limited [31, 32]. Our study demonstrates that the currently available version of ChatGPT provided comprehensive responses to questions regarding hidradenitis suppurativa.
Despite the many advantages, potential problems with LLMs must also be addressed. The answers to medical questions generated by ChatGPT are not based on evidence-based medical resources but are created by an LLM that has been trained on various Internet texts and learns reinforced by human feedback [33]. Therefore, ChatGPT may provide biased information, provided by sponsored data [33]. In addition, the use of ChatGPT and other artificial intelligence (AI) tools in the medical literature may raise legal and ethical issues. These include potential copyright infringement, medico-legal issues, and the possibility of bias or inaccuracies in the content produced. Furthermore, not all LLM applications provide an attached source for the information given [34]. Nonetheless, future improvements in LLM technologies will likely lead to improvements in accuracy and readability [18].
The study has several limitations. We only examined responses to questions in isolation, but physicians could formulate their responses based on pre-existing physician-patient relationships, which could influence the research findings. Also, our study was conducted in English, despite it being the most popular language in the world. We do not know how ChatGPT-4 would perform in other languages. The Likert scale used in the study, although widely used in the literature, has not been rigorously validated to assess the quality, empathy, and satisfaction of responses. The patients who answered the questions came from a support group for patients suffering from hidradenitis suppurativa, thus they may have had high knowledge about the disease and higher expectations regarding the answers. Finally, several ethical issues with the use of AI assistants in healthcare need to be resolved before these technologies are deployed. These issues include the need to verify AI-generated content for accuracy and the possible falsification or falsification of information.
Conclusions
AI technology, including LLM models, may have a significant impact on online medical information and direct communication between patients and doctors in the future. The study showed that ChatGPT-4 can answer the most frequently asked questions about hidradenitis suppurativa in an easily understandable, scientifically appropriate, and generally satisfactory way. Our study revealed that even though AI answers were rated better than those of the dermatologist, patients still prefer medical doctors as a source of information. Thus, AI will not replace physicians soon, although we should undoubtedly learn to live and cooperate with it. Large language models such as ChatGPT-4 are already capable of answering medical questions in an empathetic, qualitative, and satisfying way, and we should realize that their performance will only get better over the years. Before their implementation in healthcare, several ethical and bias issues need to be resolved.







