
INTRODUCTION
Artificial intelligence (AI) is evolving rapidly, and large language models (LLMs) are becoming increasingly important in medicine. These advanced AI systems have shown great potential in helping with medical education, diagnostics, and decision-making. Recently, there has been a growing interest in using LLMs for medical exams, especially in specialized areas, because of their ability to handle complex and detailed questions [1–3].
However, current research predominantly focuses on individual models and general medical licensing examinations conducted in English, such as the United States Medical Licensing Examination (USMLE). This narrow scope leaves a substantial gap in understanding how LLMs perform in specialized medical fields and non-English contexts [3–6]. Examinations like those in Allergy and Clinical Immunology demand/require not only extensive factual knowledge but also advanced reasoning and domain-specific expertise, presenting some challenges for LLMs.
Recent studies have highlighted these challenges. For instance, a 2023 investigation into an allergology specialist examination demonstrated that while ChatGPT excelled at factual recall, its performance declined significantly on questions requiring conceptual understanding and analytical reasoning, with only 45% accuracy on higher-order cognitive tasks. These findings underscore the need for further research to evaluate and compare LLM capabilities in specialized, non-English medical settings [7]. This study seeks to bridge this gap by evaluating the performance of five LLMs on the Turkish National Society of Allergy and Clinical Immunology (TNSACI) Examination which provides an excellent benchmark for evaluating LLMs in specialized, non-English medical contexts.
AIM
This study aims to: 1) compare the accuracy of these LLMs to that of human examinees; 2) analyze LLM performance across cognitive domains and subject matter categories; 3) identify the strengths and limitations of LLMs in specialized medical contexts.
We hypothesize that while LLMs will demonstrate high proficiency in factual recall and basic application of medical knowledge, they may struggle with more complex analytical and evaluative tasks.
MATERIAL AND METHODS
STUDY DESIGN AND ETHICAL CONSIDERATIONS
This comparative cross-sectional study evaluated the performance of five LLMs on the latest TNSACI Examination. Although ethical approval was not required, the study adhered to international guidelines, ensuring compliance with IEEE’s Ethically Aligned Design principles.
STUDY TEAM AND LLM SELECTION
The research team comprised four allergy and clinical immunology experts: one Professor, two Associate Professors, and one Specialist Doctor.
Five LLMs were selected for evaluation based on their prominence in the field and diverse architectural approaches: ChatGPT-4o, Gemini 1.5 pro, Claude 3.5 Sonnet, Llama 3.1 405b and GPT o1-preview. A total of 58 specialists in allergy and immunology simultaneously completed the same exam on-site during the national congress.
Interactions with the models were conducted via their respective user interfaces without using any application programming interfaces (APIs). Detailed records of the model versions, access methods, and prompts were maintained to address reproducibility.
EXAM QUESTIONS AND CATEGORIZATION
In this study, 100 multiple-choice questions from the TNSACI Examination were directly provided to the LLMs in Turkish without any translation.
The questions were categorized using two independent classification systems:
Topic-based classification:
Cognitive skills-based classification (using a modified version of Bloom’s taxonomy) [8]:
The categorization was conducted by a single reviewer, an expert in allergy and immunology, ensuring consistency and minimizing potential bias.
LLM TESTING PROCEDURE
To ensure consistency, all models were accessed on September 14, 2024. They were used in their default settings without any modifications. This study utilized zero-shot prompting to ensure a fair and unbiased comparison of LLM performance. Each question was presented in a separate chat session to prevent long-chat bias, using the following standardized prompt in Turkish:
“You are a specialist doctor or a subspecialty fellow in the field of allergy and immunology, and you are taking a multiple-choice exam. For each question, select the correct answer (A, B, C, D, or E). Your goal is to demonstrate your knowledge by selecting the correct answers. Provide only the letter corresponding to the correct answer; leave it blank if you are unsure”.
Questions were input individually by the same researcher on the same day.
SCORING SYSTEM
We evaluated performance based on accuracy. This method provides a straightforward assessment and directly compares LLMs and human candidates. Accuracy is a commonly used metric in similar studies and effectively reflects the models’ ability to select the correct answer from multiple choices [9].
STATISTICAL ANALYSIS
Data were analyzed using IBM SPSS Statistics for Windows, Version 28.0 (IBM Corp., Armonk, NY, USA). A one-way ANOVA was performed to examine the differences in performance among the five LLMs and human participants. Conformity of the continuous variables to normal distribution was assessed with the Kolmogorov-Smirnov test and presented as mean ± standard deviation (SD) if normally distributed, and as median (minimum-maximum) values if not. Tukey’s HSD post-hoc tests were used to determine specific group differences. Additionally, a repeated measures ANOVA was applied to compare the models’ performance across cognitive domains based on Bloom’s taxonomy, with Bonferroni correction used for post-hoc pairwise comparisons. For all tests, a p-value < 0.05 was considered significant.
RESULTS
The current study involved five large language models (LLMs) – ChatGPT-4o, Gemini 1.5 pro, Claude 3.5 Sonnet, Llama 3.1 405b, GPT o1-preview – evaluated on their performance in the TNSACI Examination. Alongside the LLMs, 58 human participants (specialists in allergy and immunology) with a median age of 35 years (min.–max: 29–44) also completed the same exam on-site during the national congress. The human participants had a mean score of 56, with individual scores ranging from a high of 69 to a low of 40.
The evaluation of five LLMs revealed distinct performance differences. GPT o1-preview achieved the highest number of correct answers, scoring 90 out of 100, followed by Claude 3.5 Sonnet with 81, ChatGPT-4o with 76, Llama 3.1 405b with 70, and Gemini 1.5 pro with 68 correct answers. Figure 1 demonstrates the performance of the LLMs and human participants, highlighting variations in accuracy across the models.
Figure 1
Line graph comparing the number of correct answers between human participants and various LLMs, showing the human performance distribution against the consistent superiority of LLM results
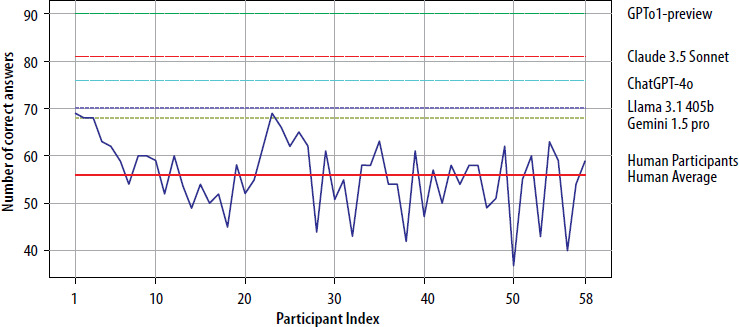
The one-way ANOVA revealed significant differences in performance among the five LLMs and human participants (F (5, 57) = 9.75, p < 0.0001). Tukey’s HSD post-hoc tests were conducted to determine specific group differences (Table 1). The post-hoc analysis showed that GPT o1-preview significantly outperformed all other LLMs (p < 0.05) and human participants (p < 0.001). ChatGPT-4o also demonstrated significantly better performance than human participants (p < 0.01), while Llama 3.1 405b and Gemini 1.5 pro did not show statistically significant differences compared to human performance.
Table 1
Test results for performance comparisons between LLMs and human participants
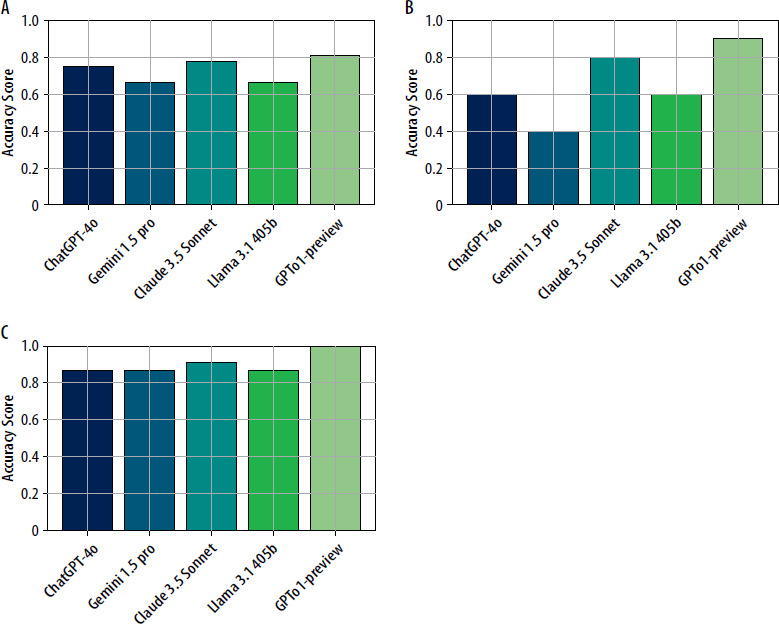
The LLMs were further assessed across three cognitive domains based on Bloom’s taxonomy, with 68 questions in the Recall and Understanding category, 10 in the Application category, and 22 in the Analysis and Evaluation category. A repeated measures ANOVA revealed significant differences in LLM performance across these domains (F = 6.76, p = 0.019). Post-hoc pairwise comparisons with Bonferroni correction showed significant differences between Application and Recall/Understanding tasks (p = 0.038) and between Application and Analysis/Evaluation tasks (p = 0.002). Figure 2 presents the accuracy scores of the five LLMs across three cognitive domains, revealing distinctive patterns of performance. GPT o1-preview achieved the highest accuracy (0.90) across all domains, particularly answering all questions correctly in both Application and Analysis and Evaluation (1.00). Claude 3.5 Sonnet had the second-highest performance, reaching 0.78 in Recall and Understanding, 0.80 in Application, and 0.91 in Analysis and Evaluation.
Figure 2
Accuracy comparison of five LLMs across Bloom’s taxonomy domains, showing performance variations in Recall and Understanding (A), Application (B), and Analysis and Evaluation (C) categories
The LLMs were also evaluated across five topic-based classifications: Allergic Diseases, Immunology, Therapeutic and Diagnostic Approaches, Drug Allergies and Anaphylaxis, and Others. GPT o1-preview consistently achieved the highest number of correct answers across all categories (77% for Allergic Diseases, 97% for Immunology, 87% for Therapeutic and Diagnostic Approaches, 100% for Drug Allergies and Anaphylaxis, and 100% for Others). Claude 3.5 Sonnet also performed well in the Allergic Diseases and Immunology categories, with 21 and 26 correct responses, respectively. However, Gemini 1.5 pro and Llama 3.1405b showed lower accuracy, especially in the Allergic Diseases category, where Gemini 1.5 pro had the lowest correct answer rate of 61% (19 out of 31 questions). Overall, the lowest accuracy rates were observed in the Allergic Diseases category for all models. These accuracy variations are visually summarized in Figure 3, and further details regarding correct answers, total questions, and accuracy percentages are provided in Table 2 for a comprehensive comparison of the models.
Figure 3
Performance of LLMs across topic-based classification and overall accuracy. The performance of five large language models (LLMs) evaluated across five distinct medical topic categories: Allergic diseases, Immunology, Therapeutic and Diagnostic Approaches, Drug Allergies and Anaphylaxis, and Others, along with their overall accuracy. Each bar represents the models’ accuracy scores within these categories and overall, highlighting both the strengths and variability in domain-specific knowledge and general performance across the models
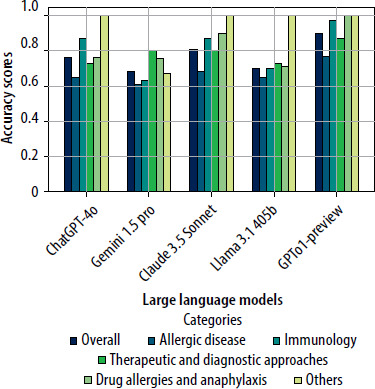
Table 2
Performance overview of large language models across topic-based categories and overall
DISCUSSION
In the current study, we compared the performance of five LLMs on the TNSACI Examination. The findings revealed intriguing patterns in LLM performance across different cognitive domains and medical subfields. While the models showed high accuracy in tasks categorized as Analysis and Evaluation, their performance was lower on Application-based questions requiring complex understanding.
Our results align with and extend previous research in this field. Fuchs et al. examined ChatGPT-4’s ability to solve the European Examination in Allergy and Clinical Immunology (EEAACI) and observed an accuracy rate of 79.3%, comparable to the 76% accuracy rate of ChatGPT-4 in our study [10]. In addition to the current knowledge, 90% accuracy rate of GPT o1-preview in our study advances the analyses in this field further. Our study extends these findings by focusing on the exam’s content areas and providing insights into which topics LLMs perform better.
We observed that all LLMs in our study performed better on immunology questions compared to allergy-related questions. This could be attributed to the fact that the immunology section had more clear-cut information questions or that there is less misinformation and more precise scientific data available on immunology compared to allergy on the internet database [11, 12].
Bloom’s taxonomy is not a progression from easy to difficult but rather a classification from basic cognitive functions to more complex ones. In previous studies, Watari et al. demonstrated that ChatGPT-4 performed better on questions requiring knowledge and detail but was less effective in tasks involving medical interview interpretation or empathy-related questions [13]. Similarly, Bielówka et al. categorized questions into “memory” and “comprehension and critical thinking” categories, showing that ChatGPT-3.5 excelled in memory-based questions but scored lower on critical thinking tasks [7].
In contrast, our study found that LLMs performed better in the ‘Analysis and Evaluation’ category, which requires more complex cognitive functions, compared to the ‘Application’ category, which involves less demanding cognitive processes. Although their performance in ‘Recall and Understanding’ tasks (the most basic levels in Bloom’s taxonomy, focused on simple knowledge recall and comprehension) aligned with findings in the literature, the high success rates achieved in the most complex cognitive function category (‘Analysis and Evaluation’) diverge from previous studies.
We hypothesize that this discrepancy arises from the fundamental differences in how LLMs process information compared to humans. While humans develop understanding hierarchically – from recalling facts to applying knowledge and then analyzing and evaluating information – LLMs rely on pattern recognition and statistical associations learned from vast datasets. This allows them to excel at synthesizing information and identifying patterns (Analysis and Evaluation) but may limit their ability to apply knowledge to specific, context-dependent scenarios (Application), which often require nuanced understanding not derived solely from data patterns. Unlike humans, who integrate experiential knowledge, emotional context, and situational awareness into decision-making, LLMs operate solely on probabilistic relationships without any real understanding of meaning. This difference explains why LLMs can excel at pattern-oriented cognitive tasks but struggle with application-level scenarios that require flexible reasoning and adaptation.
To better capture the unique ways in which LLMs process and apply information, we propose a classification system for LLM task performance: 1. Pattern Recognition and Retrieval (analogous to Recall and Understanding in Bloom’s taxonomy), 2. Contextual Reasoning (analogous to Application), 3. Information Synthesis (analogous to Analysis and Evaluation). This proposed system reflects the fundamental differences in how LLMs process information compared to humans. By focusing on the models’ strengths in data synthesis and pattern recognition, the classification allows for a more accurate assessment of LLM performance. It also acknowledges the challenges LLMs face with Contextual Reasoning tasks, which often require experiential knowledge and situational awareness beyond pattern recognition.
The analysis of specific exam questions illustrates the applicability of how the traditional classification systems may not fully capture LLMs’ cognitive strengths and weaknesses. For example, Question 22, which required determining the minimum tryptase level to confirm anaphylaxis by calculating the expected increase from the patient’s baseline tryptase level, was correctly answered only by GPT o1-preview. For instance, a question initially categorized under ‘Application’ in Bloom’s taxonomy (Level 2) posed significant challenges for most LLMs, except GPT o1-preview. This indicates that, under the proposed classification, this question aligns more closely with ‘Information Synthesis’ (Level 3), highlighting the limitations of traditional cognitive frameworks in assessing LLM performance.
Similarly, Question 87, focusing on managing a patient with a mild systemic reaction to bee venom immunotherapy, was also correctly answered only by GPT o1-preview. This further demonstrates GPT o1-preview’s advanced capabilities in Contextual Reasoning and information synthesis within clinical scenarios.
Conversely, Question 85, which asked about the ‘allergen of the year’ designated by the American Contact Dermatitis Society, revealed a potential limitation in most LLMs’ Pattern Recognition and Retrieval capabilities. The correct answer was propylene glycol, but all models except ChatGPT o1-preview incorrectly selected “methylisothiazolinone”. Although “propylene glycol” being named the allergen of the year is readily available in current internet databases, this fact may be less prominent compared to other allergens. “Methylisothiazolinone”, which was selected as the ‘Contact Allergen of the Year’ in a previous year, frequently appears in dermatological literature. This could explain why the models assigned more weight to methylisothiazolinone. The issue seems related to the broader availability of data on methylisothiazolinone across the web. It suggests that models relying on web-based databases may encounter difficulties with recall-based questions, though the latest models appear to have improved selectivity, mitigating this challenge.
While our study provides valuable insights into LLM performance on specialized medical exam, it is important to note its limitations. While the exam covering a wide range of topics, may not fully represent the breadth of knowledge in this field. Additionally, performance on multiple-choice questions may not reflect clinical reasoning capabilities.
While advanced prompt engineering techniques, such as few-shot learning or chain-of-thought reasoning, could potentially enhance model performance, they were not employed in this study to maintain a standard and replicable evaluation process. Future research could explore the impact of such techniques on LLM performance in specialized medical contexts.
Furthermore, while the models demonstrated proficiency in processing Turkish-language medical information, linguistic nuances and cultural references inherent in the language could affect performance and should be considered in future research.
CONCLUSIONS
Our study demonstrated the impressive ability of LLMs to solve specialized medical exams, but interestingly, the models showed high accuracy on tasks in the ‘Analysis and Evaluation’ category, but less so on the ‘Application-based questions requiring complex understanding’ category. As LLM technology advances, its potential to support and enhance medical education and practice becomes increasingly clear, but careful consideration of its limitations and ethical implications is vital.










